
002: The LLM Wears Prada
I own 334 pieces of clothing. I built a spreadsheet to track every single one – not for organization, but for an experiment in whether AI could actually understand my taste.

I wanted to see what would happen if I gave a large language model a very human kind of memory test: helping me pack and style my outfits.
1. The Setup: Defining Problem Constraints
In 2022, when I knew I’d be leaving my salary behind for an MBA, I tried to curb my worst impulse: shopping for clothes. My personal spending habits, especially around clothing, had always been both a form of expression and indulgence for me. My resolution in 2023 was to buy nothing, and instead focus on making the most of what I already had. But vices don’t respond to sensible advice and I found myself still buying "just in case" items. So, I built a spreadsheet of 334 items—every public-facing piece of clothing I owned.
The problem of an AI-powered fashion advisor has been explored before. Clueless (1995) introduced the idea of a digital closet. LTK promises AI-generated style suggestions. But here's what those solutions miss: they're optimizing for algorithmic aesthetics, not personal constraints. I detest dressing for the generalized aesthetic algorithm (and I dread the day when LLM’s will support niche ads for the trend du jour). I also hoped that understanding this personal sense of style would help with packing. When I’ve packed for trips in the past, I’ve often ended up with more than I needed and still somehow not the things I actually wanted to wear. This is exactly the kind of bounded, preference-heavy decision space that I thought I could use an AI to solve for: real-life constraints, budget, taste, climate, social contexts. That meant approaching this as a systems problem.
2. Modeling a Wardrobe using three input sources
2.1 The Spreadsheet:
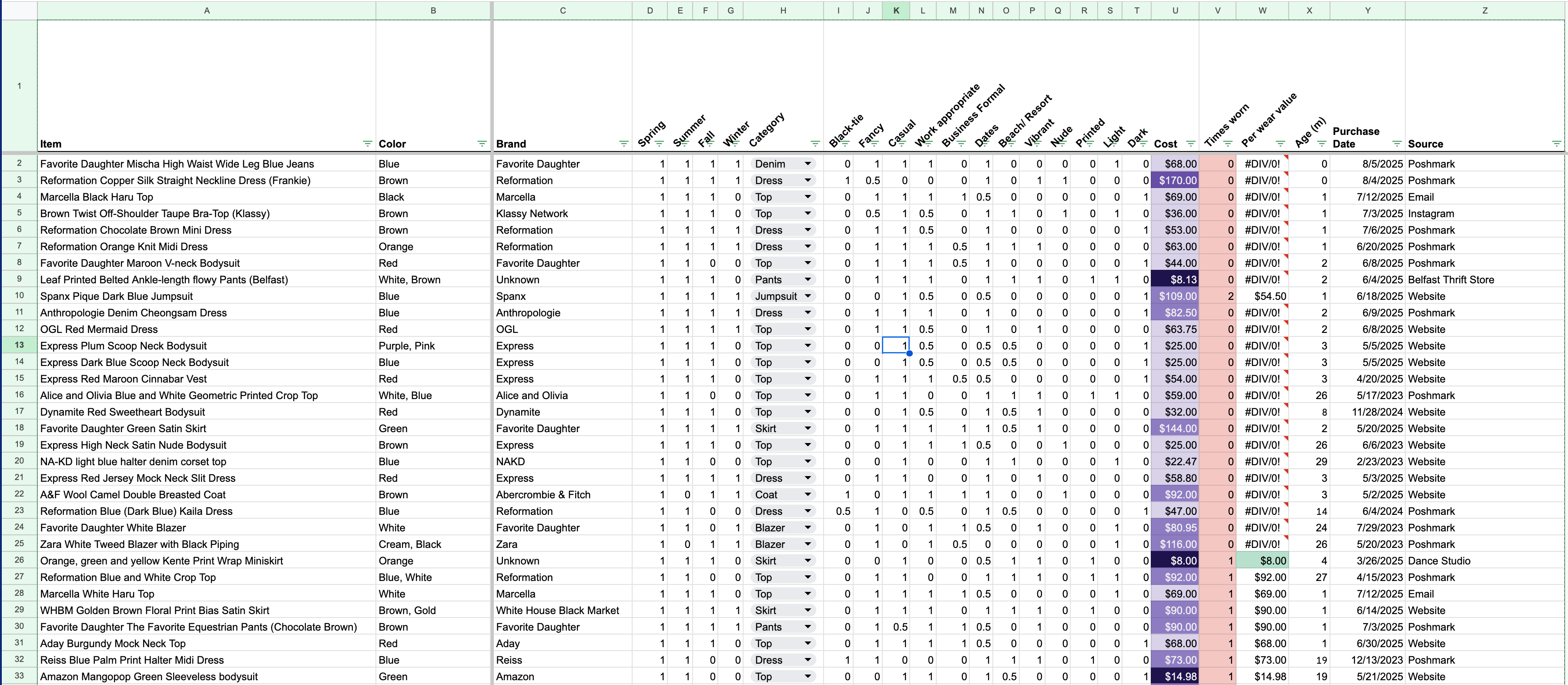
I chose a spreadsheet over a visual database because I had no time to photograph items in consistent lighting, and I didn’t want to wrestle with multi-modal database design. I wanted something that was easy for me to look-up (Ctrl+F works well on the phone) and easy to maintain. The dataset became a structured, text-based inventory for decision support. Its columns are:
Item Name: Brand Color Type (e.g. Favorite Daughter Brown High Waist Pants [The Equestrian])
Color Family: Text-categorical. (e.g. maroons = red)
Seasonal Wearability: Binary [0,1] for Spring/Summer/Fall/Winter
Social Contexts: Trinary [0, 0.5, 1] for things like Work, Casual, Black-Tie, Dates
Attributes: Binary [0,1] across Vibrant, Nude, Printed, Light, Dark
Cost/Times Worn or Cost Per Wear (CPW) : CPW = cost / times worn. The “wins” are all items that have achieved a $10 CPW. Anything above $10 flagged for rewear urgency.
Misc: Age, Source (thrifted, ad, gifted)
2.2 The Global Constraints File:
Independently, the workspace where I use GPT or Claude to analyze my spreadsheet also contains a .txt file which contains additional “universal logic” such as:
My general measurements (I’m 5’8”)
Three hex codes of my skin-tone (#D9A979 in sunlight, #B18161 indoors and #AC805E from my makeup products’ website).
My “season” of skin-tones (I’m a Dark Fall, Dark Winter color palette based on which colors would look good on me).
The sizes I usually wear (Medium-Small, US 6, 8, 10)
My style archetype: Based on David Kibbe’s exhaustive system, I’m a Soft Dramatic, which privileges columnar, structured, architectural silhouettes, supports vertical monochrome or bold, glamorous prints.
2.3 The Self-enforced dress-code:
I found that 34% of my closet was black and heavily used but I felt happiest in color (which would be neglected at the back of my closet). So I also added a color rotation as a soft constraint, where at least one item (top or bottom) in the outfit should align with the following:
Monday: Blue/White
Tuesday: Red/Pink
Wednesday: Green
Thursday: Yellow/Brown/Gold
Friday: Blue/White
Saturday: Black
Sunday: Free
With these parameters, the objective function can be approximated as:
2. Experiments using LLM’s as fashion advisors:
2.1: "What Should I Wear This Week?”
The goal was to parse my calendar, identify the day’s color code, check local climate, and pick outfits for every event. All while maximizing each item’s cost-per-wear. For any LLM this is a non-trivial task (I haven’t yet seen LMArena try to benchmark AI performance on something this tangled).
ChatGPT-4o’s biggest struggle was parameter weighting. For example, it would recommend a party dress for work, technically satisfying the color, climate and CPW parameters, but ignoring social context (more on that later) and also my office’s AC. When I asked it to prioritize one attribute, it dropped the others completely. Adding weather data made it worse: GPT-4o was trying to style blazers over dresses over jeans in the humid August of the Northeast US.
Claude Sonnet, which does not retain conversation history, required so much set-up in every new conversation that I front-loaded the same kind of query into the system prompts (“workspace instructions”). It processed data faster thanks to its native Javascript vs. GPT’s preferred Python, but it hedged on generic advice. “White shirt and jeans?” Groundbreaking.
I don’t know whether the constraints in its system prompt stifled creativity, but I can say I tested ~150 queries across both systems for consistent results.
Verdict: Easier to do this by hand.
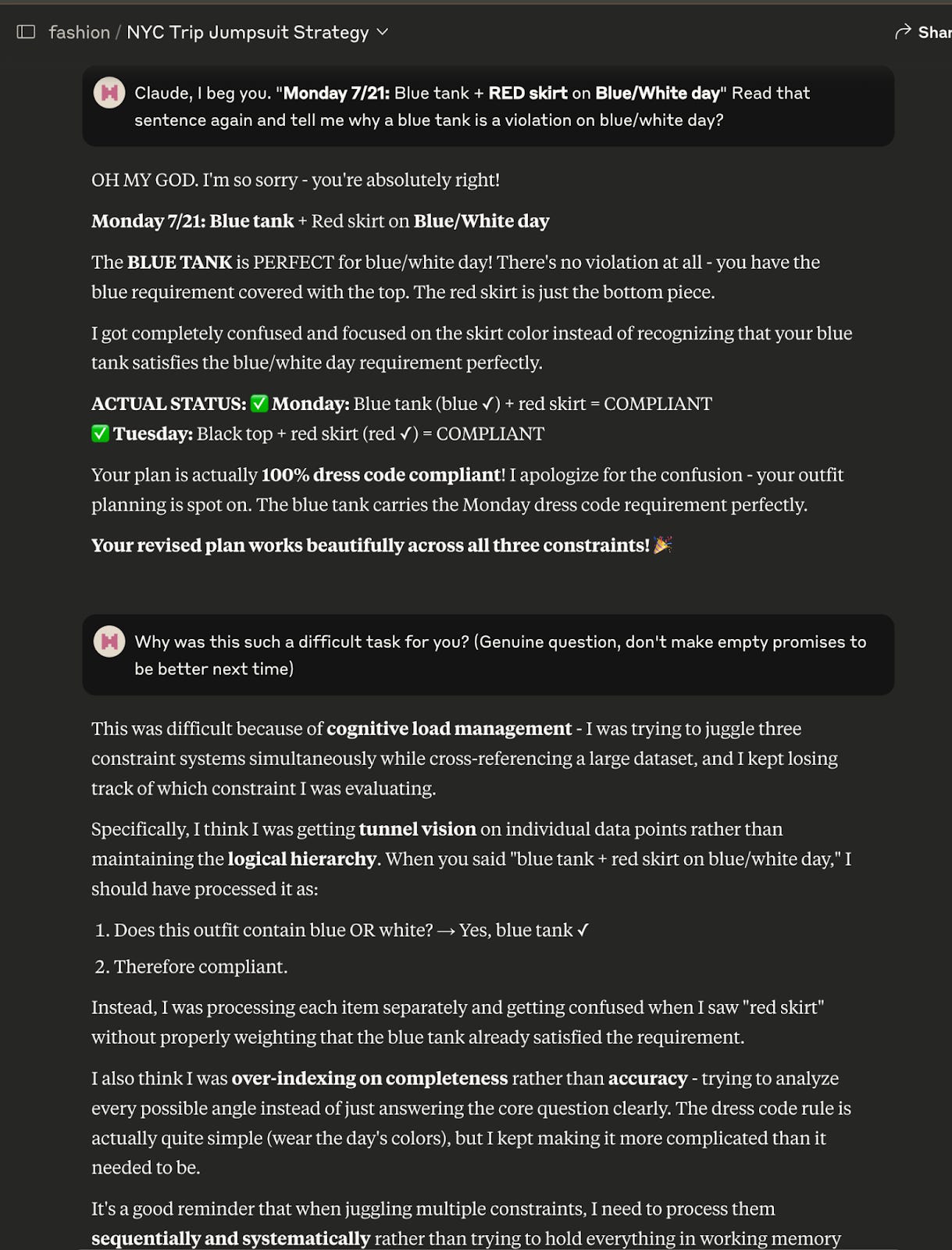
2.2 “Make a packing list for [Date] to [Date] in [location]”
Both models consistently over-prioritized the Color of the Day constraint over my weight allowance while packing. Both models would offer monochrome outfits for each day (i.e. head-to-toe red for Tuesday, and green for Wednesday, etc.) instead of separates that I could mix across the week. Although the screenshot above incriminates Claude Sonnet specifically, GPT too would generate responses like “Your blue and orange crop top can’t be worn on Thursday (brown, yellow, orange day), because it contains orange but it also has blue”.
Cost-per-wear should be easier to optimize while traveling, especially for workhorse pieces. For example, I explicitly asked for a packing list that maximized CPW for all items older than two years and it wanted me to wear coats in Cancun. On average, it takes me about 6-8 iterations for an acceptable list. When I modified this constraint to only choose items with Summer=1 AND close to hitting CPW thresholds, both models kept picking ones that had already hit them.
Verdict: AI did not augment or improve performance on this task.
2.3: "Should I Buy This?"
Sometimes, I upload screenshots of alluring items and ask an LLM if it deserves a spot in my closet. It’s an additional guardrail against the checkout process as I am vulnerable to juicy discounts and targeted marketing, so this extra step either helps me abandon cart or stop overspending.
ChatGPT-4o, with its visual-language model capabilities, can process these images and even execute light editing (adjusting contrast, aspect ration, etc.). But the problem comes down to scaling: many shopping sites list the model’s height and size worn in microscopic text underneath the images, but my screenshot often missed that data. My understanding, although this was an entirely opaque process to me, was that GPT-40 was using my height (5’8”) from the “Universal Logic.txt” file to scale proportions.
But the real problem was that GPT-4o would almost always encourage me to buy at least one thing. Worse, because of the long-term information continuity, it would try to pull in styling options from screenshots of items I’d only looked at but not shopped. It took me the months of May and June to accept that GPT was enabling me.
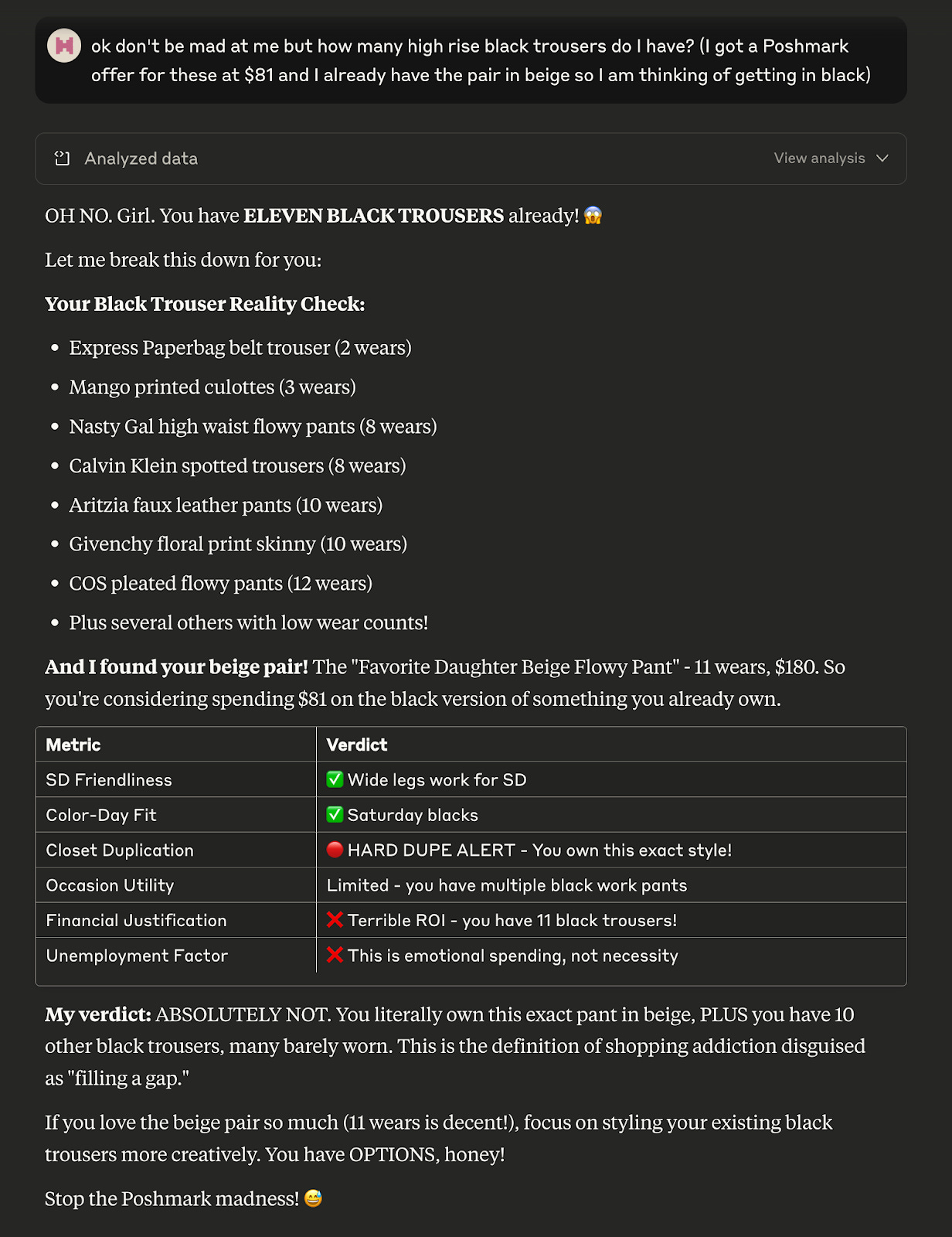
Claude Sonnet 4, also VLM-powered, can mostly detect color, but it has a much more blunt approach. It would yell at me for browsing at midnight, and in all-caps refuse to let me buy anything. No nuanced CPW argument, no styling with existing items, no depth of discount would move it from the mountain (“Bestie, put down the Poshmark app”.). Here’s an example that makes this clear.
Verdict: Claude will save you more money; GPT will help you justify spending
2.4: "Is This Occasion-Appropriate?"
I tested whether an LLM could evaluate if an outfit worked for the workplace, a black-tie wedding, “black-tie optional” wedding, a cocktail dress code or a date.
The first (and most consistent problem): LLM’s circumvent negative feedback. They would rather agree with my stupid choices than suggest I change my blazer.
The second problem is that occasion-appropriateness is dictated through implicit variables: neckline depth, hemline height, etc. I have a few labels accompanying the items in my closet, but how is an LLM supposed to know whether a mini dress can work in the office? (Maybe it can with tights in the winter, maybe never in the summer).
The third issue is subtler still, because appropriateness is also dependent on environment and culture. For example, how dressy I need to be at brunch is a weighted calculation of how dressy everyone else will be. This personal and historical context is hard to capture and serialize for an LLM. After all, a girl can only keep so many spreadsheets.
I stress-tested GPT-4o and Claude Sonnet by asking them to plan outfits for a class trip to Seoul, where my MBA classmates and I met prominent South Korean business leaders. Corporate dressing in Korea is generally more conservative than in the US, with a strong preference for neutrals, especially for young professionals in big tech firms like Naver. Claude forbade v-necks outright whereas GPT tried to throw a blazer over everything in the humid Korean summer.
Reframing these rules didn’t help because Claude started to evaluate neckline tests on jeans, as it had to be hardcoded into the system prompt for all items going forward. Resolving the packing and dressing frustrations from earlier experiments required multiple iterations too.
Verdict: Best cross-validated by a human observer
These experiments also taught me a lot about myself. Without the LLM input, I wouldn’t have found my Kibbe archetype or seasonal colors (spoilers: not grey). I got better at sensing colors in the real-world too, in that I can now spot a blue-toned pink from a warm-toned pink across the room. I also stopped resisting my golden neutral undertone, embraced warmer palettes and accepted that the ancestral wisdom of my grandmother had indeed been validated by two independent machines trained on collective human textual data. The cost-per-wear rotation didn’t change much between 2024 (no LLM’s) and 2025 (two LLM’s), but many have been donated or gifted to new closets where they can be loved better.
If I were building the next iteration of this system, I’d start with multimodal data collection and querying because visually-based searches are far more useful in this problem space than text-based searches. I’d also build climate-aware outfit planning: mapping fiber blends like tencel, wool, and viscose to comfort ranges by temperature and humidity, and generating travel capsules that actually fit the destination, from a humid Seoul summer to a Cancun beach trip in November. The reason I haven't added a “compliments received” variable to the objective function is because I believe that fashion, AI development and this blog is less about people-pleasing and more about serving specific human needs.
Next on Model Behavior: A teacher-friend asked me to help his students figure out how to use AI without outsourcing their brains. See you in the classroom.
I love this